Trie(트라이)
- = radix tree = prefix tree = digital search tree
- 탐색이라는 뜻의 retrieval에서 trie를 따온 것.
- 문자열 집합을 표현하는 트리 자료구조. 하나하나 비교가 아닌 key로 노드를 탐색.
- 원하는 원소를 찾는 작업을 O(M)에 해결
- 이진트리는 O(logN)*문자열의 길이 M => O(MlogN)
- 빠르지만 저장공간의 크기가 매우 크다.(자식들의 포인터를 모두 배열로 저장하고 있기때문.)
- 문자열 검색 문제에서 입력되는 문자열이 많을 경우 사용.
적용되는 기능.
- 검색엔진 사이트에서 제공하는 자동완성 및 검색어 추천기능에서 Trie 알고리즘 사용.
- 맞춤법 검사, IP라우팅 (라우터에서 packet을 포워딩해줄때 다음 라우터로 경로를 결정하기 위해 패킷의 목적지 주소와 라우팅 테이블의 각 엔트리에 있는 prefix와 비교함. 즉 라우팅 엔트리의 prefix mask를 목적지 주소에 masking한 후 prefix와 비교. 가장 많이 매칭되는 엔트리를 채택.)
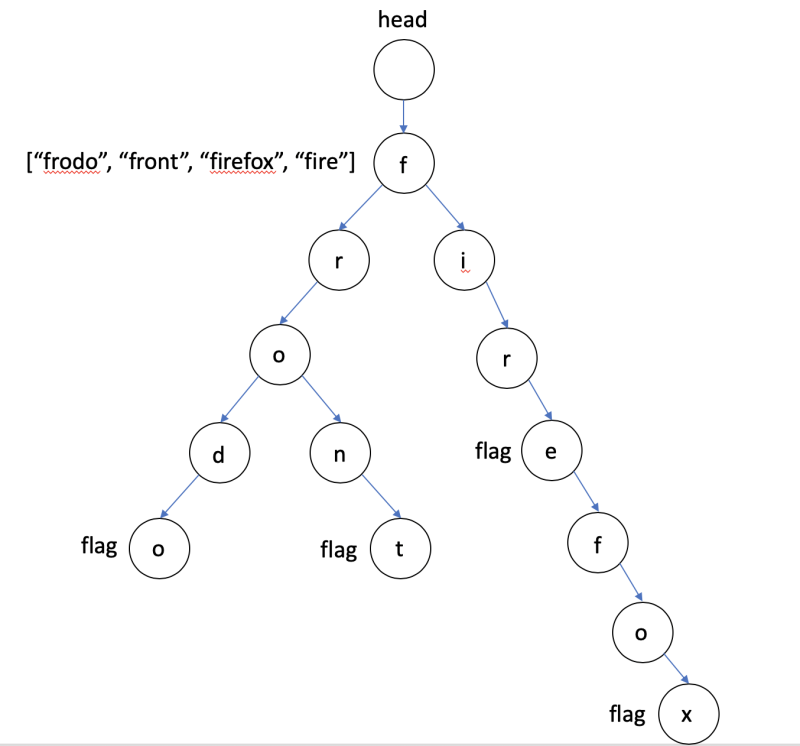
- Tree 형태, 문자열 끝을 알리는 flag가 존재.

- 이런형태로 data값에 문자열 전체를 저장.
노드
class Node(object):
def __init__(self, key, data=None):
self.key = key
self.data = data
self.children = {}key = 입력 문자
data = 문자열 종료를 알리는 flag
children = 자식 노드
Trie
class Trie:
def __init__(self):
self.head = Node(None)
def insert(self, string):
current_node = self.head
# 현재 들어온 단어들을 char별로 비교해 현재노드의 자식노드에 없다면 하나 자식 노드 새로 만들어서 넣어줌.
for char in string:
if char not in current_node.children:
current_node.children[char] = Node(char)
current_node = current_node.children[char]
# for문끝나면 현노드 data에 문자열 저장.
current_node.data = string
def search(self, string):
current_node = self.head
for char in string:
# 있으면 계속 다음 children으로 탐색.
if char in current_node.children:
current_node = current_node.children[char]
# 문자가 중간에 발견이 안되면? -> 저장된 문자가 아니니 False 반환
else:
return False
# for문 검색 끝났는데 data가 들어있으면 문자열이 있는 것. 없으면 그냥 경로일뿐 단어는 존재하지 않는 것.
if current_node.data:
return True
else:
return False
def starts_with(self, prefix):
current_node = self.head
words = []
for p in prefix:
if p in current_node.children:
current_node = current_node.children[p]
else:
return None
current_node = [current_node]
next_node = []
while True:
for node in current_node:
if node.data:
words.append(node.data)
next_node.extend(list(node.children.values()))
if len(next_node) != 0:
current_node = next_node
next_node = []
else:
break
return words- head는 빈노드로 설정
- insert함수. : 트리를 생성하기 위한 함수.
- 입력된 문자열을 하나씩 children에 확인 후 저장.
- 문자열을 다 돌면 마지막 노드의 data에 문자열을 저장(flag)
- search 함수: 문자열이 존재하는지에 대한 여부를 리턴하는 함수.
- 문자열을 하나씩 돌면서 확인 후 마지막 노드가 data가 존재한다면 True
- 그렇지 않거나 애초에 children에 존재하지 않으면 False 리턴
- starts_with 함수 : prefix단어로 시작하는 단어를 찾고 배열로 리턴하는 함수.
- 단어를 BFS로 트라이에서 찾아 반환한다.
- prefix단어까지 tree를 순회 한 이후 그 다음부터 data가 존재하는 것들만 배열에 저장하여 리턴.
예시
trie = Trie()
word_list = ["frodo", "front", "firefox", "fire"]
for word in word_list:
trie.insert(word)Trie 생성, trie에 문자열 삽입.
trie.search("friend")
>>False
trie.search("frodo")
>>True
trie.search("fire")
>>True
trie.starts_with("fire")
>>['fire', 'firefox']
trie.starts_with("fro")
>>['frodo', 'front']
trie.starts_with("jimmy")
>>None
trie.starts_with("f")
>>['fire', 'frodo', 'front', 'firefox']출력.
참고문제2 : 리트코드 - 펠린드롬 페어
from collections import defaultdict
class Node:
def __init__(self):
self.children = defaultdict(Node)
self.word_id = -1
self.palindrome_word_ids = []
class Trie:
# 삽입된 word와 id를 node를 생성. 노드는 자식, word_id, 펠린드롬 단어 id를 가짐.
def __init__(self):
self.root = Node()
# 펠린드롬을 검사하는 메서드
@staticmethod
def is_palindrome(word):
return word == word[::-1]
# 결국 핵심은
def insert(self,index,word):
node = self.root
# 단어를 뒤집어 검사하는데 만약 뒤에서 일정부분 자른 word가 펠린드롬이면 펠린드롬 단어 ids 배열에 단어의 i를 넣어줌.
for i, char in enumerate(reversed(word)):
# 다른단어 + 왼쪽 펠린드롬 부분 + 오른쪽 부분을 만족하는 단어를 찾기위함.
if self.is_palindrome(word[:len(word)-i]):
node.palindrome_word_ids.append(index)
node = node.children[char]
# 노드의 children[char]이 있으면 node로 삼고 없으면 새로 노드를 만듦
# 다 끝나면 word_id를 i로 저장.(원배열에서 위치.)
node.word_id = index
def search(self,index,word):
result = []
node = self.root
# word가 없어질때까지 순회
while word:
# 노드의 word_id가 0 이 아니다? = 단어가 있다.(오른쪽에 붙힐 단어)
if node.word_id >= 0:
# 단어가 펠린드롬을 만족한다?
if self.is_palindrome(word):
# 결과에 단어의 idex와 거꾸로 뒤집혀 삽입된 단어의 id를 넣는다.
result.append([index,node.word_id])
# word의 맨앞 글자가 node의 children에 없다면?
if not word[0] in node.children:
# 반환.
return result
# 다음 노드는 char의 아들
node = node.children[word[0]]
# word맨앞 글자는 제외.
word = word[1:]
# 다 끝났는데 단어의 id가 있다. 즉 온전히 펠린드롬을 이루는 단어가 있다면?그리고 같은 요소가 아니라면?
# 두쌍은 펠린드롬을 이루므로 결과에 삽입.
if node.word_id >= 0 and node.word_id != index:
result.append([index, node.word_id])
# 다 돌았는데 마지막노드에서 부분 펠린드롬을 이루는 녀석이 있었다면?(그 노드 앞쪽이 펠린드롬을 이룬다는 뜻.)
# 그 노드에서 끝난 부분 trie에 펠린드롬 워드가 있다면? 워드 + trie에 저장된 펠린드롬 워드의 왼쪽 + 오른쪽이 펠린드롬을 이룬다는 뜻.
for palindrome_word_id in node.palindrome_word_ids:
result.append([index, palindrome_word_id])
return result
# 단어 리스트에서 word[i] + word[j]가 펠린드롬이 되는 모든 인덱스 조합(i,j)를 구하라.
class Solution:
def palindromePairs(self, words):
trie = Trie()
# 각 문자열에 index 부여.(구분을 위함) 트라이에 삽입.
for i, word in enumerate(words):
trie.insert(i, word)
results = []
for i, word in enumerate(words):
results.extend(trie.search(i,word))
return results트라이에 역순으로 집어넣어 검사하는 방식.
'practivceAlgorithm > 자료구조&알고리즘' 카테고리의 다른 글
| [알고리즘] Tree DP (0) | 2021.09.06 |
|---|---|
| [알고리즘] sweeping-line 라인 스위핑을 통한 필터링 (0) | 2021.08.30 |
| [알고리즘] 분할정복으로 O(logN) power구현 (0) | 2021.08.25 |
| [알고리즘] Cut Vertex, Cut Edge 단절 점, 단절 선 : sub-tree의 단절 (1) | 2021.08.18 |
| [알고리즘] SCC (Strongly Connected Component) 강한 연결 요소 (0) | 2021.08.18 |