큰곰님의 10분 테코톡을 보고 정리했습니다.
메모리 계층 구조
컴퓨터 구조에서 메모리(데이터 저장매체)의 속도와 용량은 반비례관계이다.
때문에 같은 용량이라면 빠른편이 가격이 매우 높다.

- 속도가 빠른 메모리 일수록 용량이 작고
- 용량이 큰 저장장치는 속도가 느리고
- 둘다 충족하면 너무 비싸다.
- 이러한 경제논리로 데이터 저장공간은 속도와 용량에 따라 특성에 맞게 역할을 나누어 사용한다.
파레토의 법칙

원인 중 상위 20퍼센트가 전쳉 결과의 80%를 만든다는 원칙.(2대8법칙)
데이터 지역성의 원리(캐시가 유효한 이유)
자주쓰이는 데이터는 시간적 혹은 공간적으로 한 곳에 몰려 있을 가능성이 높다.
- 시간 지역성(Temporal Locality)
: 예를 들어 for문에서 조건변수(int i=0;)을 선언했을 때
해당 변수는 for문이 끝나기 전까지 계속 쓰일 확률이 높은 것.
- 공간 지역성(Spatial Locality)
: 예를 들어 for문에서 어떤 배열에 접근했을 때
해당 배열이 위치한 메모리 공간의 내용은
for문이 끝나기 전까지 계속 쓰일 확률이 높은 것.
++array[0],array[1] 다음에는 array[2]에 접근 할 확률이 높은 것을
순차 지역성(Sequential Locality)라 부르기도 함.
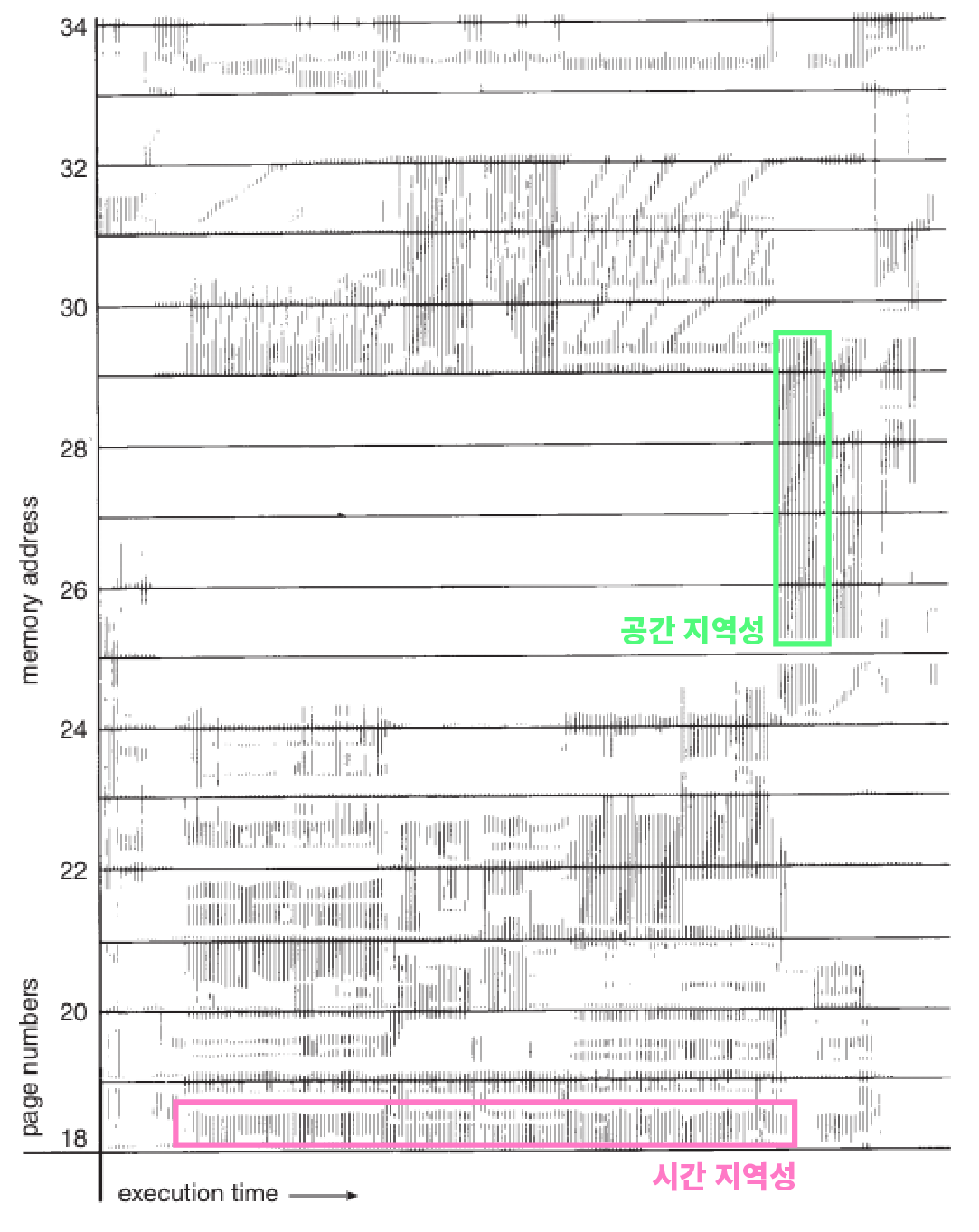
=> 이런 패턴에 따라 좀 더 효율적인 공작을 위해 고안된 것이 Cache다.
Cache란 나중에 필요할 수도 있는 무언가를 저장하였다가
신속하게 회수할 수 있는 보관 장소로, 어떤 식으로든 보호되거나 숨겨진다.
Cache의 작동방식
- 원본 데이터(system of record)와는 별개로 자주 쓰이는 데이터(Hot data)들을 복사해둘 캐시 공간을 마련한다. 캐시 공간은 상수시간 등 낮은 시간 복잡도(hash map같은)로 접근 가능한 곳을 주로 사용한다.
- 데이터를 달라는 요청이 들어오면 원본 데이터가 담긴 곳에 접근하기 전에 먼저 캐시 내부부터 찾는다.
- 캐시에 원하는 데이터가 없거나(Cache miss) 너무 오래되어 최신성을 잃었으면(Expireation) 그때서야 원본 데이터가 있는 곳에 접근하여 데이터를 가져온다. 이때 데이터를 가져오면서 캐시에도 해당 데이터를 복사하거나 혹은 갱신한다.(다시 쓸 가능성이 있기 때문)
- 캐시에 원하는 데이터가 있으면 원본 데이터가 있는 공간에 접근하지 않고 캐시에서 바로 해당 데이터를 제공한다.(Cache hit)
- 캐시 공간은 작으므로 공간이 모자라게 되면 안 쓰는 데이터부터 삭제하여 공간을 확보한다.(Eviction)
CPU, 하드디스크, 데이터베이스의 캐시 메모리
아무리 빠른 주기억장치라도 CPU의 속도를 따라가기 어려움.
그래서 SRAM이라는 특수한 메모리를 CPU에 넣어 캐시 메모리로 사용.
(캐시 메모리가 클수록 효율 향상에 매우 종요함)
하드디스크는 주기억장치에비해 10만 배 이상 느린 장치
처리 효율을 위해 자주 쓰이는 데이터를 캐싱해두는 것이 좋다.
데이터베이스도 마찬가지.
JPA의 영속성 컨텍스트도 캐시의 일종.
CDN(Content Delievery Network)
구글 글로벌 캐시를 두어 유튜브 동영상을 각 통신사마다 저장.
cdn은 캐시서버가 곳곳에 있는 개념.
웹 캐시
네트워크를 통해 데이터를 가져오는 것은 하드디스크보다 느릴 때가 많다.
=> HTML CSS JS IMG 등을 하드디스크나 메모리에 캐싱해뒀다가 다음 접속 시 재활용한다.(브라우저 캐시)
웹 서버에서 클라이언트에 보내는 HTTP 헤더에 캐시 지시자(설계자가 설계함)를 삽입하면 클라이언트 웹 브라우저에서는 해당 지시자에 명시 된 캐시 정책에 따라 캐싱을 실시한다.
캐시의 유효기간(max-age)이 지나도 캐시된 데이터가 바뀌지 않은 경우를 확인하기 위해 ETag라는 유효성 검사 토큰을 사용한다.
때로는 캐시 유효 기간을 최대한 길게 갑으면서도 정적 파일의 업데이트를 신속히 적용하기 위해 정적 파일의 이름 뒤에 별도의 토큰이나 버전 번호를 붙여야 하는 경우도 있다.(파일 이름을 바꿔버리면 캐시 유효기간을 길게 가져갈 수 있고 변경사항 현황도 쉽게 파악가능)
캐시 정책은 해당 웹페이지의 전반적인 상황에 따라 각 파일마다 다르게 적용되어야 한다.
적어도 정적 파일과 동적인 부분의 브라우저 캐싱 정책은 달라야 한다.
비공개 정보가 담긴 페이지는 보안상 캐싱을 막는 경우도 있다.
=> 웹 서버 또한 동적 웹 앱이라 하더라도 내용이 바뀌지 않는 경우가 많으므로 HTML을 캐싱해 뒀다가 다음 번 요청에 이를 재활용한다.(응답캐시)
=> 이와 유사하게 클라이언트에서 자주 요청받는 내용은 웹 서버로 전달하지 않고 웹서버 앞단의 프록시 서버에 캐싱해둔 데이터를 바로 제공하기도 함(프록시 캐시)
Redis(Remote Dictionary Server)
메모리 기반 오픈소스 NoSQL DBMS의 일종 : 여기서 Dictionary는 Hash map이고 모든데이터를 메모리에 올려서 처리한다. => 속도가 빠르다. => 캐싱에 많이쓴다.
DBMS의 일종이므로 명시적으로 삭제하지 않는 한 메모리에서 데이터를 삭제하지 않는다.(일반적인 캐시와의 차이점)
EHcache
Java의 표준 캐싱 API 명세인 JSR-107을 따르는 오픈소스 캐시 구현체
Spring 프레임워크나 Hibernate ORM 등에서 바로 사용 가능.
캐시 저장공간을 속도에 따라 나누어 자체 메모리 계층 구조를 적용할 수 있음.
메모리에 캐싱된 내용을 하드디스크에 기록 가능.
대규모 서비스에서 캐시 서버 여럿을 클러스터로 묶을 수 있는 기능을 제공.

=> 웹 서비스에서 캐시는 뺄 수 없는 존재이다.
'Computer Science > 컴퓨터 구조' 카테고리의 다른 글
| [Computer Structure] CPU (0) | 2021.09.01 |
|---|---|
| [Computer Structure] 고정소수점 & 부동 소수점 (0) | 2021.08.29 |
| [CS] Interrupt & Context Switching (0) | 2021.07.07 |